state是什么意思(Flink中的State概念及其扩容算法)
在流计算场景中,数据会源源不断的流入Apache Flink系统,每条数据进入Apache Flink系统都会触发计算。如果我们想进行一个Count聚合计算,那么每次触发计算是将历史上所有流入的数据重新计算一次,还是每次计算都是在上一次计算结果之上进行增量计算呢?答案是肯定的,Apache Flink是基于上一次的计算结果进行增量计算的。那么问题来了: "上一次的计算结果保存在哪里,保存在内存可以吗?",答案是否定的,如果保存在内存,在由于网络,硬件等原因造成某个计算节点失败的情况下,上一次计算结果会丢失,在节点恢复的时候,就需要将历史上所有数据(可能十几天,上百天的数据)重新计算一次,所以为了避免这种灾难性的问题发生,Apache Flink 会利用State存储计算结果。本篇将会为大家介绍Apache Flink State的相关内容。

什么是State
这个问题似乎有些"弱智"?不管问题的答案是否显而易见,但我还是想简单说一下在Flink里面什么是State?State是指流计算过程中计算节点的中间计算结果或米数据属性,比如 在aggregation过程中要在state中记录中间聚合结果,比如 Apache Kafka 作为数据源时候,我们也要记录已经读取记录的offset,这些State数据在计算过程中会进行持久化(插入或更新)。所以Flink中的State就是与时间相关的,Flink任务的内部数据(计算数据和米数据属性)的快照。
为什么需要State
与批计算相比,State是流计算特有的,批计算没有failover机制,要么成功,要么重新计算。流计算在 大多数场景 下是增量计算,数据逐条处理(大多数场景),每次计算是在上一次计算结果之上进行处理的,这样的机制势必要将上一次的计算结果进行存储(生产模式要持久化),另外由于 机器,网络,脏数据等原因导致的程序错误,在重启job时候需要从成功的检查点(checkpoint,后面篇章会专门介绍)进行state的恢复。增量计算,Failover这些机制都需要state的支撑。
State 存储实现
Flink内部有三种state的存储实现,具体如下:
基于内存的HeapStateBackend - 在debug模式使用,不 建议在生产模式下应用;
基于HDFS的FsStateBackend - 分布式文件持久化,每次读写都操作内存,同需考虑OOM问题;
基于RocksDB的RocksDBStateBackend - 本地文件+异步HDFS持久化;
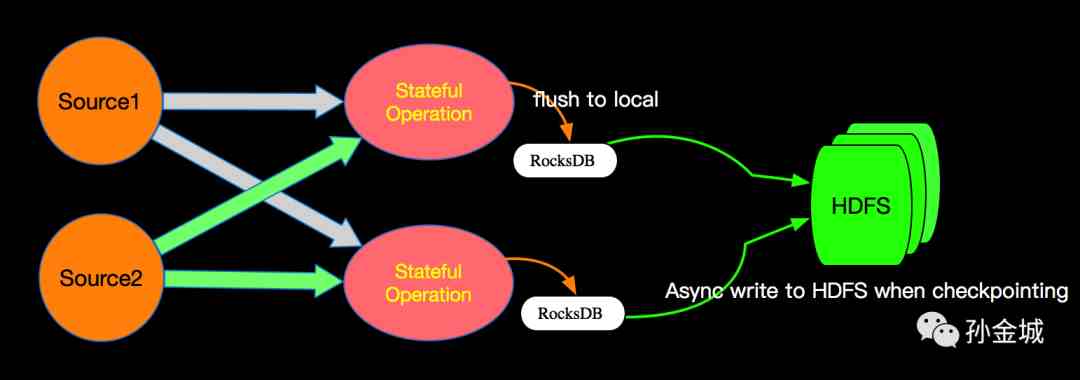
State存储的架构
Apache Flink 默认是RocksDB+HDFS的方式进行State的存储,State存储分两个阶段,首先本地存储到RocksDB,然后异步的同步到远程的HDFS。这样的而设计既消除了HeapStateBackend的局限(内存大小,机器坏掉丢失等),也减少了纯分布式存储的网络IO开销。
State 分类
KeyedState - 这里面的key是我们在SQL语句中对应的GroupBy/PartitioneBy里面的字段,key的值就是groupby/PartitionBy字段组成的Row的字节数组,每一个key都有一个属于自己的State,key与key之间的State是不可见的;
OperatorState - Flink内部的Source Connector的实现中就会用OperatorState来记录source数据读取的offset。
State在扩容时候的重新分配
Flink是一个大规模并行分布式系统,允许大规模的有状态流处理。为了可伸缩性,Flink作业在逻辑上被分解成operator graph,并且每个operator的执行被物理地分解成多个并行运算符实例。从概念上讲,Flink中的每个并行运算符实例都是一个独立的任务,可以在自己的机器上调度到网络连接的其他机器运行。
Flink的DAG图中只有边相连的节点有网络通信,也就整个DAG在垂直方向有网络IO,在水平方向如下图的stateful节点之间没有网络通信,这种模型也保证了每个operator实例维护一份自己的state,并且保存在本地磁盘(远程异步同步)。通过这种设计,任务的所有状态数据都是本地的,并且状态访问不需要任务之间的网络通信。避免这种流量对于像Flink这样的大规模并行分布式系统的可扩展性至关重要。
如上我们知道Flink中State有OperatorState和KeyedState,那么在进行扩容时候(增加并发)State如何分配呢?比如:外部Source有5个partition,在Flink上面由Source的1个并发扩容到2个并发,中间Stateful Operation 节点由2个并发并扩容的3个并发,如下图所示:
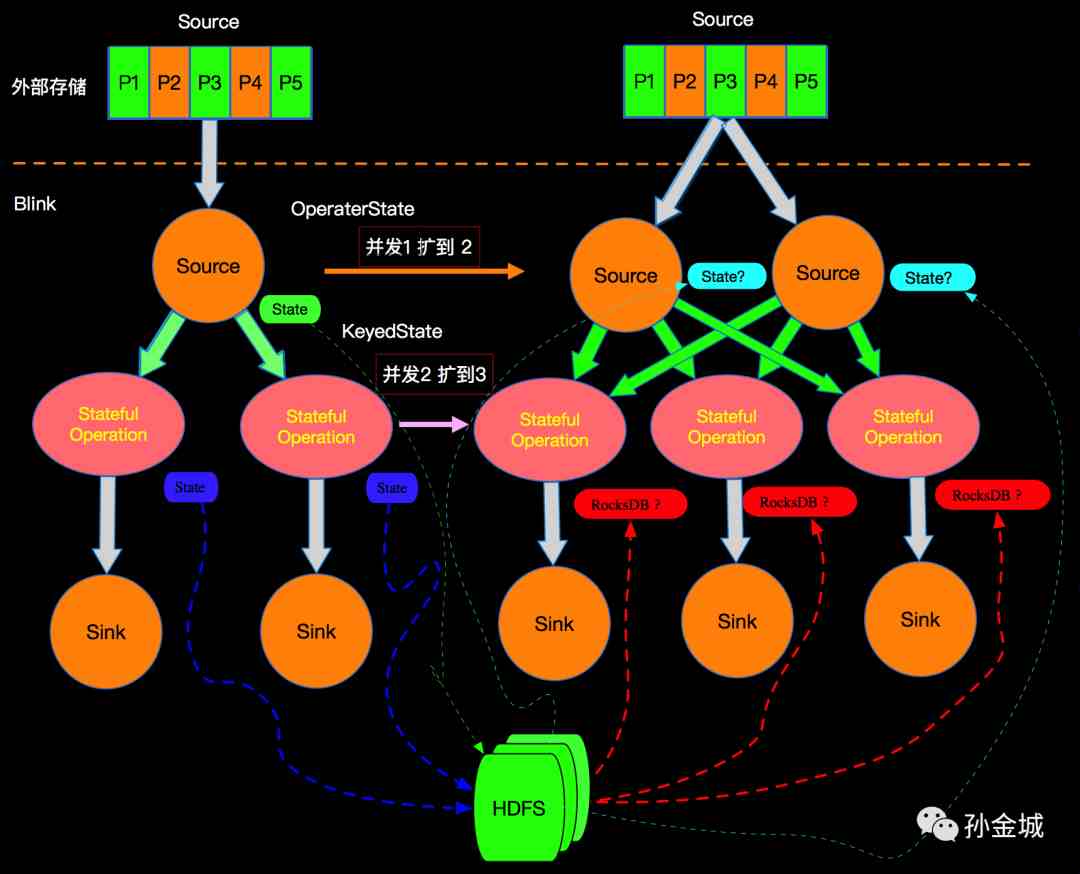
在Flink中对不同类型的State有不同的扩容方法,接下来我们分别介绍。
OperatorState对扩容的处理
我们选取Flink中某个具体Connector实现实例进行介绍,以MetaQ为例,MetaQ以topic方式订阅数据,每个topic会有N>0个分区,以上图为例,假设我们订阅的MetaQ的topic有5个分区,那么当我们source由1个并发调整为2个并发时候,State是怎么恢复的呢?
State 恢复的方式与Source中OperatorState的存储结构有必然关系,我们先看MetaQSource的实现是如何存储State的。首先MetaQSource 实现了ListCheckpointed<T extends Serializable>,其中的T是Tuple2<InputSplit,Long>,我们在看ListCheckpointed接口的内部定义如下:
public interface ListCheckpointed<T extends Serializable> { List<T> snapshotState(long var1, long var3) throws Exception; void restoreState(List<T> var1) throws Exception;
}
我们发现 snapshotState方法的返回值是一个List<T>,T是Tuple2<InputSplit,Long>,也就是snapshotState方法返回List<Tuple2<InputSplit,Long>>,这个类型说明state的存储是一个包含partiton和offset信息的列表,InputSplit代表一个分区,Long代表当前partition读取的offset。InputSplit有一个方法如下:
public interface InputSplit extends Serializable { int getSplitNumber();
}
也就是说,InputSplit我们可以理解为是一个Partition索引,有了这个数据结构我们在看看上面图所示的case是如何工作的?当Source的并行度是1的时候,所有打partition数据都在同一个线程中读取,所有partition的state也在同一个state中维护,State存储信息格式如下:

- 发表于 2021-03-04 23:28
- 阅读 ( 269 )
- 分类:互联网
671 篇文章